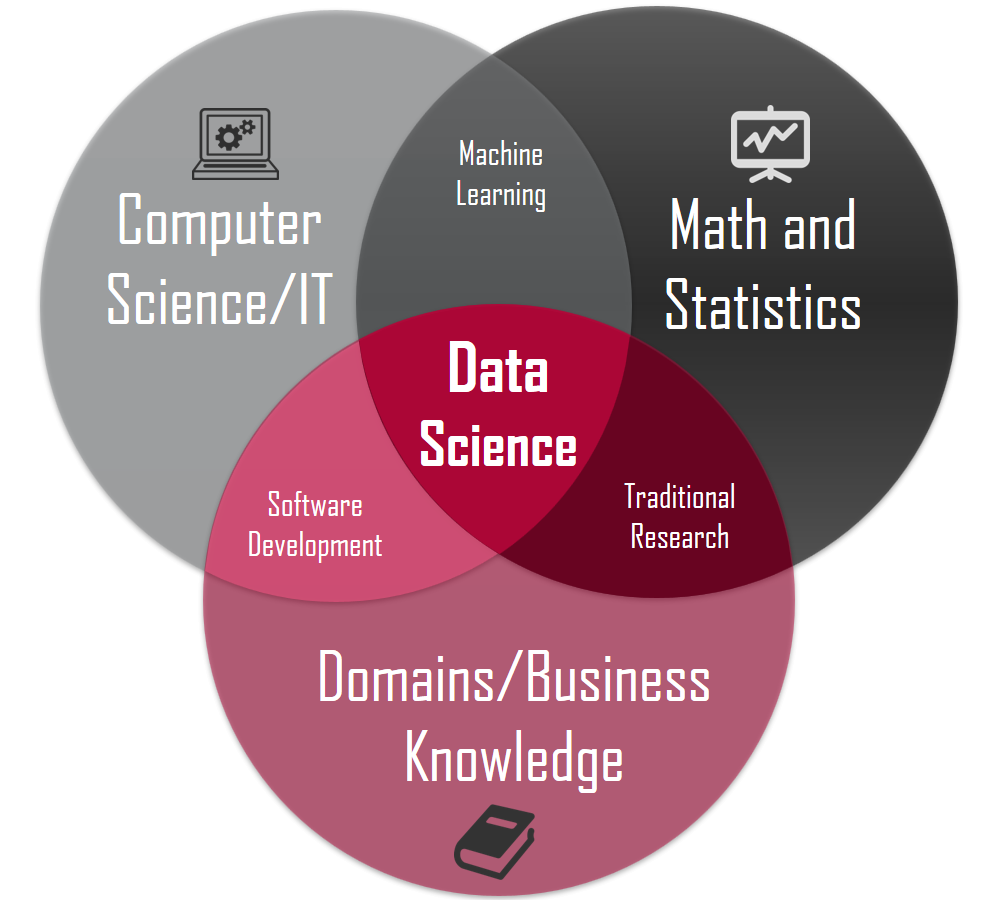
Data science, at its core, is the art of deriving actionable insights from data. It combines domain and business knowledge to frame meaningful questions, mathematics and statistics to analyze and interpret data, and computer science and programming to develop algorithms and tools for data processing. This interdisciplinary field empowers organizations to make informed decisions, optimize operations, and innovate by harnessing the full potential of data, ensuring that data-driven solutions are not only technically sound but also aligned with real-world goals and challenges.
Let’s explore each of these area’s in bit more depth
Domain and Business Knowledge
Domain and business knowledge are invaluable assets in the field of data science. They provide the context and understanding necessary to transform raw data into meaningful insights and actionable strategies that can drive real-world impact. In this introduction, we will explore why domain and business knowledge are crucial components of successful data science endeavors.
- Contextual Understanding: Domain knowledge refers to expertise in a specific industry or field, such as healthcare, finance, or e-commerce. This knowledge is essential because it allows data scientists to understand the nuances and intricacies of the data they work with. Without this context, data may be misinterpreted, leading to flawed analyses and misguided decisions.
- Problem Definition: Business knowledge helps data scientists identify and define relevant problems and opportunities within an organization. Understanding the goals, challenges, and key performance indicators (KPIs) of a business or industry is critical for framing data-driven projects effectively. Without this understanding, data scientists may focus on irrelevant or low-impact issues.
- Data Relevance: Domain knowledge enables data scientists to distinguish between relevant and irrelevant data. Not all data is equally valuable, and knowing what data points are meaningful in a specific context is crucial for efficient analysis. Business expertise guides data scientists in selecting the right data sources and variables to work with.
- Feature Engineering: In machine learning, feature engineering involves creating new features or transforming existing ones to improve model performance. Domain knowledge helps in identifying which features are likely to be predictive or useful for solving a particular problem, saving time and resources in the modeling process.
- Interpretation and Communication: Data scientists are often tasked with explaining their findings to non-technical stakeholders. Business knowledge allows them to translate complex data insights into actionable recommendations that resonate with decision-makers. Effective communication is essential for driving change based on data-driven insights.
- Ethical Considerations: Understanding the ethical and regulatory aspects of a specific domain is critical. Domain knowledge helps data scientists navigate potential ethical dilemmas, such as issues related to data privacy, bias, and fairness, which are especially important in fields like healthcare and finance.
- Iterative Problem Solving: Domain knowledge fosters an iterative problem-solving approach. Data scientists can leverage their understanding of the domain to refine their analyses and models as they gather more data and insights, leading to more effective and impactful solutions over time.
- Competitive Advantage: Businesses that integrate domain knowledge with data science gain a competitive advantage. By leveraging data insights in combination with industry expertise, organizations can make informed strategic decisions, optimize operations, and innovate in ways that competitors without such knowledge cannot.
In conclusion, domain and business knowledge are indispensable to the practice of data science. They bridge the gap between data and actionable insights, ensuring that data-driven solutions are not only technically sound but also aligned with the goals and challenges of the real world. Data scientists who possess both technical skills and domain expertise are better equipped to deliver value to their organizations and drive positive outcomes in today’s data-driven landscape.
Math and Statistics
Mathematics and statistics are foundational disciplines that play a crucial role in the field of data science next to domain and business knowledge. They provide the fundamental tools and techniques necessary for understanding, analyzing, and extracting meaningful insights from data. In this introduction, we will explore why mathematics and statistics are so essential to data science.
- Data Understanding: Data science begins with data, and mathematics and statistics are essential for understanding and summarizing complex datasets. Descriptive statistics, such as mean, median, and standard deviation, allow data scientists to get a quick overview of data characteristics, while mathematical concepts like linear algebra help in organizing and representing data.
- Data Exploration: Exploratory data analysis is a critical step in data science. Statistical techniques help in identifying patterns, outliers, and trends within data. Visualization tools, often built upon statistical principles, enable data scientists to create informative graphs and charts for better data comprehension.
- Inferential Statistics: Data scientists often need to make inferences about populations based on sample data. Inferential statistics, including hypothesis testing and confidence intervals, provide a rigorous framework for drawing conclusions from data and assessing the reliability of these conclusions.
- Predictive Modeling: Machine learning, a core component of data science, relies heavily on mathematical algorithms. Linear regression, decision trees, neural networks, and many other machine learning techniques are rooted in mathematical principles. Statistical concepts, like cross-validation, are also used to evaluate and fine-tune models.
- Optimization: Many data science tasks involve optimization problems, such as finding the best parameters for a model or minimizing a cost function. Mathematical optimization techniques, including gradient descent and linear programming, are essential for solving these problems efficiently.
- Probability Theory: Probability theory is the foundation of statistics and plays a critical role in modeling uncertainty in data. In data science, probability distributions and Bayesian methods are used for various tasks, such as probabilistic modeling, hypothesis testing, and Bayesian inference.
- Data Validation: Ensuring data quality and reliability is vital in data science. Statistical methods help in data validation, identifying inconsistencies, and dealing with missing values.
- Feature Engineering: Selecting and engineering relevant features from data is a crucial step in building effective machine learning models. Mathematical techniques, such as dimensionality reduction and feature scaling, aid in feature selection and preprocessing.
- A/B Testing: Businesses often use A/B testing to make data-driven decisions about product changes or marketing strategies. Statistics is essential for designing experiments, analyzing results, and determining whether observed differences are statistically significant.
- Ethical Considerations: Understanding the ethical implications of data science and machine learning requires a grasp of statistical fairness and bias mitigation techniques, which are rooted in statistical theory.
In summary, mathematics and statistics provide the theoretical framework and practical tools necessary for data scientists to extract valuable insights, make informed decisions, and build predictive models from data. They underpin the entire data science process, from data collection and exploration to modeling and interpretation, making them indispensable to the field of data science.
Computer Science and Programming
Computer science and programming are the cornerstones of data science, serving as the essential tools and frameworks that enable the extraction, analysis, and interpretation of valuable insights from vast and complex datasets. In this introduction, we will explore why computer science and programming are of paramount importance to the field of data science.
- Data Handling and Processing: Data science begins with data, and computer science provides the infrastructure and algorithms to efficiently store, retrieve, and manipulate data. Programming languages and databases are the building blocks for data storage, retrieval, and preprocessing, allowing data scientists to work with data of varying sizes and formats.
- Algorithm Development: Computer science principles are at the heart of the algorithms that power data analysis and machine learning. These algorithms enable data scientists to uncover patterns, make predictions, and solve complex problems. Writing code to implement and customize these algorithms is a fundamental aspect of data science.
- Data Visualization: Data scientists use programming languages and libraries to create informative data visualizations. These visual representations help in understanding data patterns and trends, as well as in communicating findings to non-technical stakeholders.
- Machine Learning and AI: Machine learning, a core component of data science, heavily relies on computer science concepts. Developing and training machine learning models involve writing code to process data, define model architectures, and optimize performance.
- Automation and Efficiency: Programming allows data scientists to automate repetitive data-related tasks, making data analysis more efficient and scalable. This automation is critical when dealing with large datasets or performing routine data preprocessing.
- Data Integration: In many data science projects, data must be collected from various sources and integrated into a cohesive dataset. Computer science and programming are essential for building data pipelines that extract, transform, and load (ETL) data from multiple sources.
- Scalability: Handling big data requires scalable solutions, and computer science provides the knowledge and tools to design and implement systems that can process and analyze massive datasets efficiently.
- Version Control: Programming principles like version control systems (e.g., Git) are crucial for managing code and collaborative work in data science projects. They ensure the integrity of code and facilitate teamwork among data scientists.
- Custom Solutions: Data science often requires custom solutions tailored to specific problems or datasets. Programming empowers data scientists to develop unique algorithms and applications to address these challenges effectively.
- Problem Solving: Computer science fosters a problem-solving mindset that is invaluable in data science. Data scientists use programming to experiment with different approaches, iterate on solutions, and tackle complex data-related issues systematically.
In summary, computer science and programming are the backbone of data science, enabling data scientists to transform data into actionable insights and drive decision-making across various domains. The synergy between these fields empowers data scientists to leverage technology and innovation in their quest to extract knowledge and value from the ever-expanding realm of data.
Conclusion
Data science is a dynamic discipline that thrives at the intersection of domain and business knowledge, math and statistics, and computer science and programming. It leverages these critical pillars to uncover hidden insights, solve complex problems, and drive data-informed decisions. With domain expertise, it contextualizes data within specific industries. Math and statistics provide the analytical foundation for data exploration and modeling, while computer science and programming enable data collection, storage, and algorithm development. Together, these elements form a powerful synergy that fuels innovation, efficiency, and strategic advantage, making data science an indispensable asset in our data-driven world.