Data science is a dynamic and multidisciplinary field that revolves around extracting valuable insights and knowledge from vast and complex datasets. It merges expertise from various domains, including statistics, computer science, and domain-specific knowledge, to uncover patterns, trends, and actionable information. Data scientists leverage cutting-edge tools and techniques to transform raw data into meaningful solutions, making data science an essential driver of informed decision-making across diverse industries.
A Brief History of Data Science
Data science, as a distinct field, has evolved rapidly over the past few decades, but its roots can be traced back to various disciplines that have long been involved in the pursuit of knowledge through data analysis.
- Statistics: The foundations of data science lie in statistics, which has been around for centuries. Statisticians like Sir Francis Galton, who pioneered the concept of correlation, and Sir Ronald A. Fisher, known for his work in experimental design, laid the groundwork for statistical methods that are now fundamental to data analysis.
- Computer Science: The advent of computers in the mid-20th century revolutionized data handling and processing. Pioneers like Alan Turing and John von Neumann contributed significantly to the development of computer science, which became an essential component of data science.
- Data Mining: In the 1990s, data mining emerged as a key precursor to data science. Researchers began developing algorithms and techniques to extract valuable patterns and information from vast datasets.
- Big Data: The 21st century saw the explosion of Big Data, driven by the proliferation of digital technology and the internet. The need to manage, analyze, and derive insights from massive datasets gave rise to new tools and methodologies, propelling data science into the mainstream.
- Machine Learning and AI: The integration of machine learning and artificial intelligence into data science has opened new frontiers. Innovations in algorithms, neural networks, and deep learning have enabled data scientists to tackle complex problems in fields ranging from healthcare to finance.
- Data Science as a Discipline: As data science became increasingly vital across industries, it evolved into a distinct field. Universities started offering data science programs, and organizations established data science teams to leverage data for decision-making.
Today, data science is ubiquitous, with applications in finance, healthcare, marketing, and more. It continues to evolve with advancements in technology and the ongoing quest to harness the power of data for a better understanding of the world and more informed decision-making.
Sentiment Analysis
Calculating the prior probability in sentiment analysis using Naive Bayes is a fundamental step in training the model. The prior probability represents the likelihood of each sentiment class occurring in the dataset, independent of the specific words or features in the text. To calculate the prior probabilities, follow these steps:
- Data Preparation:
- First, gather your labeled dataset, where each data point (text sample) is associated with a sentiment label (e.g., positive or negative).

- Count the Occurrences of Each Sentiment Class:
- Count the number of instances for each sentiment class (e.g., positive, negative) in above training dataset. Let’s denote these counts as
N_positive,N_negative.
- Count the number of instances for each sentiment class (e.g., positive, negative) in above training dataset. Let’s denote these counts as
- Calculate the Total Number of Samples:
- Calculate the total number of samples in training dataset. This is the sum of all sentiment class counts:
N_total = N_positive + N_negative- N_total = 2 + 2 = 4
- Calculate the total number of samples in training dataset. This is the sum of all sentiment class counts:
- Calculate the Prior Probability for Each Class:
- To calculate the prior probability (P(class)) for each sentiment class, divide the count of samples in that class by the total number of samples:
- For positive sentiment:
P(positive) = N_positive / N_total - For negative sentiment:
P(negative) = N_negative / N_total 
- For positive sentiment:
- Repeat this calculation for all sentiment classes present in your dataset, if it has more sentiment classes
- To calculate the prior probability (P(class)) for each sentiment class, divide the count of samples in that class by the total number of samples:
These calculated prior probabilities represent the probability of encountering each sentiment class in your dataset. In the context of Naive Bayes, these probabilities are used as the prior probabilities when estimating the likelihood probabilities of words or features for each class.
Use the computational methods to determine and extract the subjective information from the sample dataset given above:

During training phase, we classify the words in the vocabulary based on positive or negative sentiments text phrase as given below
| Word | # in positive sentiment | # in negative sentiment |
| love | 1 | 0 |
| good | 1 | 0 |
| movie | 2 | 2 |
| terrible | 0 | 1 |
| bad | 0 | 1 |
| like | 1 | 0 |
| watch | 1 | 0 |
| hate | 0 | 1 |
| boring | 0 | 1 |
Probability of word in a positive review P(word | positive)
(# of occurrence of word in positive review) / (Total # of words in positive review)
Probability of words in negative review P(word | negative)
(# of occurrence of word in negative review) / (Total # of words in negative review)
Training and calculation of probability of sentiment:

Calculating sentiment analysis for a word phrase:
“Loved the movie, good to watch”
After removing the stop words in the phrase
LOVE MOVIE GOOD WATCH
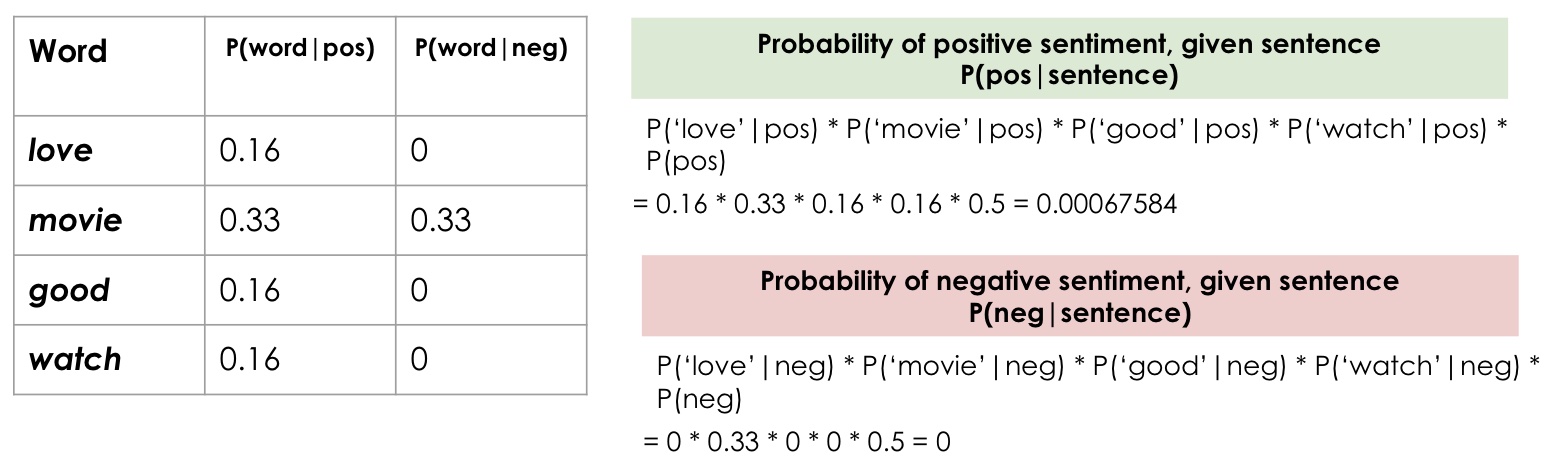
Applying normalization and identifying the sentiments of the test phrase:

Hence, the test phrase “Loved the movie, good to watch” is of positive sentiment
Summary:
Sentiment analysis, also known as opinion mining, holds a pivotal role in overseeing textual data in diverse customer engagement contexts. It enables the extraction of emotional nuances from text, facilitating informed decision-making and actions. One prevalent technique in this domain is Naive Bayes, which leverages prior probabilities and evidence to compute posterior probabilities. Naive Bayes boasts advantages such as scalability, efficiency, and consistency, making it a valuable tool for sentiment analysis across various applications.